Michael McConnell:
Top doesn't display CPU usage of ipchains or ipvsadm. vmstat doesn't display CPU usage of ipchains or ipvsadm.
Joe
ipchains and ipvsadm are user tools that configure the kernel. After you've run them, they go away and the kernel does it's new thing (which you'll see in "system"). Unfortunately for some reason that no-one has explained to me "top/system" doesn't see everything. I can have a LVS-DR director which is running 50Mbps on a 100Mpbs link and the load average doesn't get above 0.03 and system to be negligable. I would expect it to be higher.
Julian 10 Sep 2001
Yes, the column is named "%CPU", i.e. the CPU spend for one process related to all processes. As for the load average, it is based on the length (number of processes except the current one) of the queue with all processes in running state. As we know, LVS does not interract with any processes except the ipvsadm. So, the normal mode is the LVS box just to forward packets without spending any CPU cycles for processes. This is the reason we want to see load average 0.00
OTOH, vmstat reads /proc/stat and there are the counters for all CPU times. Considering the current value for jiffies (the kernel tick counter) the user apps can see the system, the user and the idle CPU time. LVS is somewhere in the system time. For more accurate measurement for the CPU cycles in the kernel there are some kernel patches/tools that are exactly for this job - to see what time takes the CPU in some kernel functions.
The number of active/inactive connections are available from the output of ipvsadm.
Julian 22 May 2001
Conns is a counter and is incremented when a new connection is created. It is not incremented when a client re-uses a port to make a new connection (Joe, - the default with Linux).
director:/etc/lvs# ipvsadm IP Virtual Server version 0.2.12 (size=16384) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP lvs2.mack.net:0 rr persistent 360 -> RS2.mack.net:0 Route 1 0 0 -> RS1.mack.net:0 Route 1 0 0 TCP lvs2.mack.net:telnet rr -> RS2.mack.net:telnet Route 1 0 0 -> RS1.mack.net:telnet Route 1 0 0 |
You can monitor connections with snmp.
Dennis Kruyt d (dot) kruyt (at) zx (dot) nl 30 Jun 2004
I use lvs-snmp (http://anakin.swiss-support.net/~romeo/lvs-snmp/) and cacti to graph the connections.
AJ Lemke
I am running a 2 node lvs-cluster and was wonder if the list could recommend a traffic monitoring program. My LVS is the frontend for a reverse proxy cache and I would like to know the traffic that each VIP is handling. I need to know the data rates on a per ip basis. I use mrtg at the switch level but I need to have more granularity, hence the need for per IP basis.
Kjetil Torgrim Homme kjetilho (at) ifi (dot) uio (dot) no 11 Jul 2004
munin (http://www.linpro.no/projects/munin/) has a plugin for this. you can get the numbers you need with ipvsadm
# ipvsadm -L -t smtp:smtp --stats Prot LocalAddress:Port Conns InPkts OutPkts InBytes OutBytes -> RemoteAddress:Port TCP smtp.uio.no:smtp 1508879 38457326 0 10461M 0 -> mail-mx6.uio.no:smtp 374117 9490846 0 2664M 0 -> mail-mx3.uio.no:smtp 377646 9961956 0 2543M 0 -> mail-mx2.uio.no:smtp 378502 9288837 0 2707M 0 -> mail-mx1.uio.no:smtp 378614 9715687 0 2546M 0 # ipvsadm -L -t smtp:smtp --rate Prot LocalAddress:Port CPS InPPS OutPPS InBPS OutBPS -> RemoteAddress:Port TCP smtp.uio.no:smtp 7 85 0 20480 0 -> mail-mx6.uio.no:smtp 1 17 0 1126 0 -> mail-mx3.uio.no:smtp 1 17 0 2023 0 -> mail-mx2.uio.no:smtp 2 26 0 6681 0 -> mail-mx1.uio.no:smtp 2 25 0 10650 0 |
Cyril Bouthors:
Where can I get the info originally in /proc/net/ip_vs_stats and removed since 0.9.4?
Wensong Zhang wensong (at) gnuchina (dot) org 20 Nov 2001
for global stats /proc/net/ip_vs_stats
You can get per-service statistics by
ipvsadm -Ln --stats -t|u|f service-address |
If you want to program to get statistics info, use libipvs. Here's the writeup that went with the original code.
Packet throughput (in 64-bit integers) is in /proc/net/ip_vs_stats or /proc/net/ip_masq/vs_stats. The counters are not resetable, you have to keep the previous reading and substract. Output is in hexadecimal.
Here's the statistics
director:# more /proc/net/ip_vs_stats TotalConns InPkts OutPkts InBytes OutBytes 98F9 13945999 13609E49 613AD3B2F 4F90FE6F9E Virtual Service Pro VirtService Conns InPkts OutPkts InBytes OutBytes TCP C0A8026E:0000 4 12 0 00000043B 000000000 TCP C0A8026E:0017 7 3A9 0 00000C3A5 000000000 Real Service Pro VirtService RealService Conns InPkts OutPkts InBytes OutBytes TCP C0A8026E:0000 C0A8010C:0000 4 14 0 0000004B4 000000000 TCP C0A8026E:0000 C0A8010B:0000 1 3 0 0000000B4 000000000 TCP C0A8026E:0017 C0A8010C:0017 4 A2 0 00000232A 000000000 TCP C0A8026E:0017 C0A8010B:0017 4 32A 0 00000A827 000000000
Joe
Can I zero out these counters if I want to get rates, or should I store the last count?
Ratz, May 2001
There was a recent (2 months ago) talk about zeroing in-kernel counters and I'm not so sure if all the kernel hacker gurus agreed but:
You must not zero a counter in the kernel!
I didn't really understand the arguments against or pro zeroing counters so I'm not a big help here, but if others agree we certainly can add this feature. It would be ipvsadm -Z as an analogy to ip{chains|tables}. BTW, we are proud of haveing 64-bit counters in the kernel :)
Storing ... there are different approaches to this (complexity order):
- Use a script that extracts the info and writes it flat to a file
Use MRTG or rrdtool since I reckon you wanted to use the stats to generate some graphics anyway. These tools handle the problem for you.
MRTG requires SNMP, but you can have a slightly modified snmpd.conf and execute a script that parses /proc/net/ip_masq/vs_stats and writes it into a file. The advantage of this over the first one is, that you can write the current number into one file and mrtg will know how to draw the graph.
I give you an example:
We have a customer named plx. Now he has only one service and 2 realserver. We extended the snmpd.conf with following lines:
exec lbsessions /bin/sh /opt/tac/snmp/lbsessions exec lbsessions.plx.total /bin/sh /opt/tac/snmp/lbsessions.plx.total exec lbsessions.plx.web-web1 /bin/sh /opt/tac/snmp/lbsessions.plx.web-web1 exec lbsessions.plx.web-web2 /bin/sh /opt/tac/snmp/lbsessions.plx.web-web2
The scripts are awk scripts that get the information accordingly to the service or the realserver. You can then do a table walk of the OID 1.3.6.1.4.1.2021.8 to see what your values are:
snmpwalk $IP $COMMUNITY .1.3.6.1.4.1.2021.8
Example output if everything is ok:
enterprises.ucdavis.extTable.extEntry.extNames.1 = lbsessions enterprises.ucdavis.extTable.extEntry.extNames.2 = lbsessions.plx.total enterprises.ucdavis.extTable.extEntry.extNames.3 = lbsessions.plx.web-web1 enterprises.ucdavis.extTable.extEntry.extNames.4 = lbsessions.plx.web-web2 enterprises.ucdavis.extTable.extEntry.extCommand.1 = /bin/sh /opt/tac/snmp/lbsessions enterprises.ucdavis.extTable.extEntry.extCommand.2 = /bin/sh /opt/tac/snmp/lbsessions.plx.total enterprises.ucdavis.extTable.extEntry.extCommand.3 = /bin/sh /opt/tac/snmp/lbsessions.plx.web-web1 enterprises.ucdavis.extTable.extEntry.extCommand.4 = /bin/sh /opt/tac/snmp/lbsessions.plx.web-web2 enterprises.ucdavis.extTable.extEntry.extResult.1 = 0 enterprises.ucdavis.extTable.extEntry.extResult.2 = 0 enterprises.ucdavis.extTable.extEntry.extResult.3 = 0 enterprises.ucdavis.extTable.extEntry.extResult.4 = 0 enterprises.ucdavis.extTable.extEntry.extOutput.1 = 292 enterprises.ucdavis.extTable.extEntry.extOutput.2 = -1 enterprises.ucdavis.extTable.extEntry.extOutput.3 = -1 enterprises.ucdavis.extTable.extEntry.extOutput.4 = -1
Here you see that the total amount of sessions of the load balancer serving about 8 customers is 292 currently and that customer plx has no connections so far.
- Write a MIB for LVS stats.
There are a family of monitoring tools descended from MRTG. These now include RRDtool (a descendant of MRTG, written by the same author, Tobias Oetiker) and wrappers around RRDtool like lrrd (which have spawned their own family of programs, e.g. cricket, to monitor and graph just about anything you like). lrrdtool can/does use nagios.
Laurie Baker lvs (at) easytrans (dot) com 20 Jan 2004
Nagios is a monitoring tool previously known as Netsaint.
I've read the documentation for mrtg and several of its descendants and haven't been about to figure out how they work enough to get them going. While the syntax of all of the commands is available, there is no global picture of how they are used to make a working set of programs. I saw Tobias give a talk at Usenix one year about MRTG and while I knew what it did, I didn't know how to set it up. Some people have got these packages going, presumably needing less documenation that I do. I'd like a worked example of how a single simple variable (e.g. the contents of /proc/loadavg) is sampled and plotted. The accompanying packages needed (e.g. SNMP, php, gd...) are not described. While a competent sysadmin will be able to work out what is missing from the output of the crashes, it would be better to prepare ahead of time for the packages needed, so that you can plan the time for the install and won't have to stop for lack of information that you could have handled ahead of time.
 | Note |
|---|---|
| This was the first attempt to produce a graphical monitoring tool for LVS. It doesn't seem to be under active developement anymore (Apr 2004) and people are now using rrdtool (or ganglia which uses rrdtool) (see below). | |
| Note |
|---|---|
Alexandre has a new address Alexandre (dot) Cassen (at) free (dot) fr and moved his pages to Alexandre's open source code (http://www.lnxos.net/). The links below to Alexandre's pages are dead. You can find files here lvsgsp-0.0.4.tar.gz (http://www.austintek.com/LVS/LVS-HOWTO/HOWTO/files/lvsgsp-0.0.4.tar.gz). alex alshu (at) tut (dot) by 20 May 2008 has provided lvsgsp_newscripts.tar.bz2 (http://www.austintek.com/LVS/LVS-HOWTO/HOWTO/files/lvsgsp_newscripts.tar.bz2) that he uses with lvsgsp. | |
Alexandre Cassen alexandre (dot) cassen (at) wanadoo (dot) fr, the author of keepalived has produced a package, LVSGSP that runs with MRTG to output LVS status information. Currently active and inactive connections are plotted (html/png).
The LVSGSP package includes directions for installing and a sample mrtg.cfg file for monitoring one service. The mrtg.cfg file can be expanded to multiple services
WorkDir: /usr/local/mrtg IconDir: /usr/local/mrtg/images/ # VS1 10.10.10.2:1358 Target[VS1]: `/usr/local/bin/LVSGSP 10.10.10.2 1358` Directory[VS1]: LVS MaxBytes[VS1]: 150 . . # VS2 10.10.10.2:8080 Target[VS2]: `/usr/local/bin/LVSGSP 10.10.10.2 8080` Directory[VS2]: LVS MaxBytes[VS2]: 150 . . |
A note from Alexandre
Concerning the use of MRTG directly onto the director, we must take care of the computing CPU time monopolised by the MRTG graph generation. On a very overloaded director, the MRTG processing can degrade LVS performance.
Peter Nash peter (dot) nash (at) changeworks (dot) co (dot) uk 18 Nov 2003
I'm using a perl script to pull LVS statistics from my directors into MRTG using the ucd-snmp-lvs module. I'm sure this could be easily modified to work with RRDTool. I'm no perl programmer so I'm sure there are better ways to do this but it's been working for me for the last 3 months. Since my MRTG runs on a remote server (not the directors) using SNMP gives me the remote access I need. The main problem to overcome was that the "instance number" of a particular "real service" is dependent on the order in which the services are added to the IPVS table. If you are using something like ldirectord to add/remove services then this order can vary, so the script has to solve this problem. I also had a few problems getting the ucd-snmp-lvs module to compile with net-snmp on my RH8 directors but that was probably down to my lack of knowledge, I got there in the end!
The MRTG call to the script is as follows (director names, SNMP community and IP addresses are "dummies"):
Target[lvs-1]: `/home/agents/snmpipvsinfo.pl director1 communitystring 123.123.123.123 80 bytes` + `/home/agents/snmpipvsinfo.pl director2 communitystring 123.123.123.123 80 bytes` |
This aggregates the results from both primary and backup director so it doesn't matter which one is "active". The script returns zeros if the requested service is not currently in the LVS table on the target director.
#!/usr/bin/perl
#
============================================================================
# LVS Stats info script for mrtg
#
# File: snmpipvsinfo.pl
#
# Author: Peter Nash 17/06/03
#
# Version: 1.0
#
# Purpose: Uses SNMP to get the IPVS stats on an LVS director.
# Needs to find the correct instance in the lvsServiceTable to
# match a given virtual server (the instance number
# depends on the order in which services are added).
#
# Usage: ./snmpipvsinfo.pl director community service_ip service_port [conn|packets|bytes]
#
# Notes: The instance number of a given service in the LVS table
# depends on the order in which the services are added to the table.
# For example, if a monitoring service such as ldirectord is used
# to add/remove services to LVS then the instance number of a service
# will be based on the polling sequence of ldirectord. As services are
# added or removed the instance numbers of existing services may
# change. Therefore this script has to determine the current SNMP
# instance number for each LVS service every time it is run.
# In addition to the director address and SNMP community if takes the
# service IP and service PORT as parameters to identify a specific
# service. The last option determines the static to return.
# Output is in MRTG compatible format.
#
============================================================================
$director=shift;
$community=shift;
$service_ip=shift;
$service_port=shift;
$mode=shift;
$instance="";
# First we need to find the LVS instance for this service
# Get all service addresses
@addresses=`snmpwalk -v 2c -c $community -m LVS-MIB $director
lvsServiceAddr`;
# Get all the service ports
@ports=`snmpwalk -v 2c -c $community -m LVS-MIB $director lvsServicePort`;
# Now for each service check to see if both address and port match
foreach $i (0 .. $#addresses) {
($address,)=splitnamevalue($addresses[$i]);
($port,$thisinstance)=splitnamevalue($ports[$i]);
if ( $address =~ /$service_ip/ ) {
if ( $port =~ /$service_port/ ) {
$instance=$thisinstance;
}
}
}
# Now we've got the instance for the service get the requested data
if ( $instance eq "") {
# If the instance does not exist return zero's (i.e. this may be the
backup director)
$param1="0: = 0";
$param2="0: = 0";
} else {
if ( $mode eq "conn" ) {
$param1=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsConns.$instance`;
$param2=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsConns.$instance`;
} elsif ( $mode eq "packets" ) {
$param1=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsInPkts.$instance`;
$param2=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsOutPkts.$instance`;
} elsif ( $mode eq "bytes" ) {
$param1=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsInBytes.$instance`;
$param2=`snmpget -v 2c -c $community -m LVS-MIB $director lvsServiceStatsOutBytes.$instance`;
} else {
$param1="";
$param2="";
print "Error in mode parameter";
}
}
# Get the uptime
$uptime=`snmpwalk -v 2c -c $community $director sysUpTime.0`;
$uptime =~ s/.*\)\s+(\w+)/$1/;
($value1,)=splitnamevalue($param1);
($value2,)=splitnamevalue($param2);
print "$value1\n";
print "$value2\n";
print "$uptime";
print "LVS $mode\n";
sub splitnamevalue {
$namevalue=shift;
chomp($namevalue);
($index,$value)=split(/ = /, $namevalue);
$index =~ s/.*\.([0-9]{1,6})$/$1/;
$value =~ s/.*:\s+(\w+)/$1/;
return $value,$index;
}
|
Salvatore D. Tepedino sal (at) tepedino (dot) org 21 Nov 2003
I posted the new version on my site: http://tepedino.org/lvs-rrd/. The new version has a lot of code cleanup, much more flexibility in the coloring, a command line arg so you can just graph traffic to one port (ie: just port 80 traffic), and the update script has been changed slightly to remove a redundant loop (Thanks Francois! If I do something that obviously silly again, you can smack me!) and the removal of the need to specify what type of LVS yours is (Route, Masq, etc). Now it should collect data on all servers in the LVS. Next step is to figure out how to graph specific services (VIP/Port combinations instead of just specific ports)...
| Note |
|---|---|
| Jun 2006. tepedino.org is not on the internet. The last entry in the wayback machine is 10 Feb 2005. Leon Keijser e-mailed me lvs-rrd-v0.7.tar.gz (http://www.austintek.com/WWW/LVS/LVS-HOWTO/HOWTO/files/lvs-rrd-v0.7.tar.gz) which has a Changelog of Jan 2006. | |
| Note |
|---|---|
| Sebastian Vieira sebvieira (at) gmail (dot) com 10 Nov 2006 | |
For those interested, the website of lvs-rrd is back up again at its usual address: http://tepedino.org/lvs-rrd/
Joe: I contacted Sal off-list, to find there'd been problems at the ISP. He's back, with the same e-mail address etc. v0.7 is still his latest code. If the server goes down again, you can contact him sal (dot) tepedino (at) gmail (dot) com.
21 Jan 2004
This new version allows you to graph connections to a specific VIP or realserver or VIP port or RS Port or any combination of those via command line options. It also adds in adds an option flip the graph for people with more inactive than active connections. Also it can spit out an HTML page for the specific graphs it created so a simple one line php page (included) can run the script and display the output.
| Note |
|---|---|
| Joe: various people (including Francois Jeanmougin) have started sending patches to Salvatore. | |
17 Jan 2004
This new version allows you to graph connections to a specific VIP or realserver or VIP port or RS Port or any combination of those via command line options. It also adds in adds an option flip the graph for people with more inactive than active connections (you can have either the ActiveConn or InActConn plotted in the negative region below the X-axis). Also it can spit out an HTML page for the specific graphs it created so a simple one line php page (included) can run the script and display the output.
Joe - Jan 2004: lvs-rrd worked straight out of the box for me. You first install rrdtool from http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/ with the standard ./configure ; make ; make install. The rrdtool executables are standard ELF files (not perl scripts as I thought). rrdtool has the libraries it needs (zlib,
director:/usr/local/rrdtool-1.0.45/bin# ldd rrdtool libm.so.6 => /lib/libm.so.6 (0x40017000) libc.so.6 => /lib/libc.so.6 (0x4003a000) /lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000) |
gd) so you don't need any recursive downloading. Then you follow Salvatore's "Setup" instructions and you'll soon have gifs showing the activity on your LVS.
The filenames that Salvatore uses for his databases are derived from the ipvsadm (hex) information in /proc/net/ip_vs. Thus one of my rrd files is lvs.C0A8026E.0017.C0A8010C.0017.rrd representing VIP:port=192.168.2.110:23, RIP:port=192.168.1.12:23. You don't have to look at these files (they're binary rrd database files) and naming them this way was easier than outputting the IP in dotted quad with perl. Salvatore supplies utilites (which he grabbed off the internet) to convert the IP:ports between dotted quad and hex.
#/bin/bash
# from the internet, modified by Salvatore Tepedino and Joseph Mack
#
#IP is output in dotted quad
#run this in the directory with the lvs.*.rrd files.
#The files will have a name like
#lvs.C0A8026E.0017.C0A8010C.0017.rrd
#
#here's an example run
# # ls
# lvs.C0A8026E.0017.C0A8010C.0017.rrd
# # ./ip_hex2quad.sh
# 192.168.2.110.0.23.192.168.1.11.0.23
#
#-----------------------
for file in lvs*rrd
do
#echo $file
IP=$(echo $(echo $file | tr a-z A-Z | sed 's/LVS\.//;s/\.RRD//;s/\.//g;s/\(..\)/;\1/g;s/^/i
base=16/' | bc) | sed 's/ /./g')
echo $IP
done
#----------------------------
|
and
#/bin/bash
#ip_quad2hex.sh
#$1 is IP in dotted quad format
#converts dotted quad IP to hex
#------------------------
for i in `echo $1 | sed 's/\./ /g'`;do echo $i |awk '{printf "%02X", $1}';done;echo
#------------------------
|
Tore Anderson tore (at) linpro (dot) no 07 Dec 2003
There is also LRRD. Plugins for monitoring ipvsadm output are already included, for an demonstration you could take a look at "screenshot" pages at http://linpro.no/projects/lrrd/example/runbox.com/cujo.runbox.com.html
| Note |
|---|---|
| Joe: Tore is one of the lrrd developers. | |
After getting Salvatore's code running, I reviewed the lrrd docs and tutorials to realise that there never was any hope of me understanding them without outside help. The docs are written for data coming from snmp, and I assumed that snmp was the only way of getting data. As Salvatore's code shows, rrdtool can use data from anywhere: if you can retreive/fetch/get your data in a script and send it as a parameter to rrdtool, then you can store and graph it with rrdtool.
taqu taqumd (at) gmail (dot) com 25 Nov 2008
Hi, I recently created another LVS graphing tool. This scripts parse ipvsadm -L -n --stats --exact and generate the following graphs: Project Home (http://sourceforge.jp/projects/lvs-stats) Screen Shot (http://sourceforge.jp/projects/lvs-stats/wiki/FrontPage)
cacti is another rrdtool based monitoring tool, which has been adapted for lvs.
Bruno Bonfils asyd (at) debian-fr (dot) org 26 Jan 2004
If there are some of you who running cacti in order to monitor LVS cluster, you'll probably interest by my xml data query and the associate template. Both are available on http://www.asyd.net/cacti/.
Karl Kopper karl (at) gardengrown (dot) org 03 Dec 2003
Another cool tool for monitoring the Real Servers is Ganglia. (With version 2) you run gmond monitoring daemons on each RS and a single gmetad daemon to poll the gmonds on a server (that is running Apache) outside the cluster. Then with the Ganglia Web Frontend you get great color graphs that help you to find "hot spots". You can then write your own gmetric script to create your own custom graph for anything happening on the Real Servers (I suppose you could cull the Apache logs for "GET" operations--check out the Gmetric Script Repository). Incidentally, you can also add the gexec program to submit batch jobs (like cron jobs) to the least loaded realserver or to all nodes simultaneously.
Ganglia Page: http://ganglia.sourceforge.net/ Sample Ganglia page: http://meta.rocksclusters.org/Rocks-Network/ Gmetric Script Repository: http://ganglia.sourceforge.net/gmetric/ |
| Note |
|---|---|
ganglia is designed for beowulfs. It produces nice colored graphs which managers love and I'm sure lots of beowulfs have been sold because of it. However there is a catch 22 with using it. The compute nodes on a beowulf run synchronously, calculating a subset of a problem. At various points in a calculation, results from the compute nodes need to be merged and all compute nodes halt till the merge finishes. The merge cannot start till all nodes have finished their part of the calculation and if one node is delayed then all the other nodes have to wait. It is unlikely that the ganglia monitoring jobs will run synchronised to the timeslice on each compute node. Thus in a large beowulf (say 128 nodes), it will be likely that one of the compute nodes will have run a ganglia job and the other 127 will have to wait for this node to complete its subset of the main calculation. So while ganglia may produce nice graphs for managers, it is not compatible with large or heavily loaded beowulfs. None of this affects an LVS, where jobs on each realserver run independantly. Ganglia should be a good monitoring tool for LVSs. | |
ganglia is a package for monitoring parameters on a set of nodes, forwarding the data to a display node where the data is displayed as a set of graphs. By default ganglia displays such things as load_average, memory usage, disk usage, network bandwidth. Instructions in the documentation show how to add graphs of your own parameters. The data on the display node is stored by rrdtool.
| Note |
|---|---|
| The documentation was not clear to me and the installation took several attempts before I got a working setup. These notes are written on the 3rd iteration of an install, It's possible that I handled something in an earlier iteration that I forgot about. | |
Ganglia has the ability to use gexec by Brent Chun, a tool to remotely execute commands on other nodes (like rsh and ssh). You can configure ganglia to run with or without gexec. Unfortunately I couldn't get gexec to run properly on Linux and on contacting the author (Mar 2004) I find that gexec was developed under another OS (*BSD ?) and because of problems with the Linux pthread implementation, doesn't work on Linux. He's working on fixes.
Karl Kopper karl (at) gardengrown (dot) org 11 Apr 2004
Matt Massie of the Ganglia project tried to pull the gexec code into the new Ganglia distro but failed due to this pthreads problem as I understand it, but if you download the old gexec and authd packages directly from Brent's (old) web page I don't think they have the pthreads problem. Well, actually, there is a problem we've had with gexec when you try to run a command or script on all nodes (the -n 0 option) that we've never fully examined. The problem causes the -n 0 option to be so unreliable we don't use. The "-n 1" option works fine for us (we use it for all production cron jobs to select the least loaded cluster node).
For the moment you might be better off using the same ssh keys on all cluster nodes and writing a script (this is the way I like to do it now when I have to reliably run a command on all nodes). The great thing about gexec, though, is that it will run the command at the same time on all nodes--the ssh method has to step through each node one at a time (unless, I supposed you background the commands in your script). Hmmm... Theres an idea for a new script...
| Note |
|---|---|
| gexec has similar functionality to dancer's shell - dsh which uses ssh or rsh as transport layer. Using ssh as a transport layer has its own problems - you need passphrase-less login when using ssh for dsh, but you need passphrase enabled login for users starting their sessions. | |
There are 3 types of nodes in ganglia
monitored nodes:
these will be your realserver and director(s) (i.e. all machines in the LVS). These nodes run gmond, the ganglia monitoring demon, which exchanges data with other monitored nodes by multicast broadcasts. gmond also exchanges data with the relay nodes.
relay nodes:
these run gmetad. For large setups (e.g. 1024 nodes), gmetad collects data from gmond in tree fashion and feeds the data to the GUI node (which is also running gmond). gmetad like gmond exchanges data by multicast broadcasts.
I didn't quite figure out what was going on here and since I only had a small LVS, I just ran gmetad on the GUI node.
I assume if you had (say) 8 LVS's running and one GUI machine, that gmond would be running on all nodes and that gmetad would be running on
- at least one node that was guaranteed to be up in each LVS. For an LVS with a failover pair of directors, gmetad would run on both directors.
- the GUI node.
I didn't figure out how to set up a gmetad node, if it wasn't also the GUI node. From gmetad.conf, it would appear that each gmetad keeps its own set of rrd database files (presumably these are duplicates of the set on the GUI node). Presumably you should keep the rrd database files in the same location as for the GUI node (for me in DocumentRoot/ganglia/rrds/), just to keep things simple, but I don't know.
gmetad is not happy if you shut it down while gmond is running, so I modified the gmetad init file to first shutdown gmond.
node with the GUI:
this node collects the data with gmetad, stores it with rrdtool, and displays it in a webpage using the php files in gmetad-webfrontend. This machine requires apache (I used apache-2.x.x) and php4.
On an LVS with a single director, the node with the GUI will likely be the director. In an LVS with an active/backup pair of directors, you would probably have both directors run gmetad and have the GUI running (with gmetad) on an administrative machine.
If you like using netstat -a and route rather than their -n counterparts, then you can add the following -
/etc/services #from ganglia gmond 8649/tcp # gmond gmond 8649/udp # gmond gmetad_xml 8651/tcp # gmetad xml port gmetad_int 8652/tcp # gmetad interactive port |
/etc/hosts 239.2.11.71 gmond_mcast |
Ganglia is installed differently depending on the role of the machine in the data path.
machines being monitored: these run gmond.
gmond is found in the ganglia-monitor-core. To run gmond you do not need rrdtool to be installed. However compilation of gmond requires /usr/lib/librrdtool.a and /usr/include/rrd.h. Unless you already have these available, you will first have to compile rrdtool on the monitored node. After compilation of rrdtool, you don't have to install it, just copy rrd.h and librrd.a to their target directory. To compile rrdtool, you need to have perl installed to produce the rrd manpages (I needed perl-5.8.0, perl-5.6.1 produced errors). I couldn't see anyway in the Makefile of just producing librrd.a. A make lib; make lib_install option would be nice here.
After installing librrd.a and rrd.h, do the default ganglia-monitor-core install: ./configure; make; make install. This will install /usr/bin/gmetric, /usr/bin/gstat and /usr/sbin/gmond. Set up the rc file gmond/gmond.init to start gmond on boot. Copy the default conf_file gmond/gmond.conf to /etc/ and although you will have to modify it shortly, for now don't mess with it. gmond does not need a conf file to start and will assume the values in the default conf file if the conf file doesn't exist.
Now see if you can start gmond - you should see 8 copies in the ps table. There are several things that can go wrong at this stage, even if gmond starts.
There is no log file for gmond. To figure out problems, you turn on debug in gmond.conf. After doing this, gmond will not detach and will send the debug output to the console.

Warning Do not leave debug on through a reboot, as the gmond rc file won't exit and the boot process will hang. gmond may not start.
I got the debug message "gmond could not connect to multicast channel" when using an older (2.4.9) kernel, but not with a newer (2.4.20) kernel.
- If you have a multi-homed machine, gmond defaults to using eth1. If the other machines aren't mulitcast accessable via eth1, you won't know: gmond will happily broadcast out the wrong NIC, but will never hear anything back. If you watch the debug output, you will see messages about packets being sent out, but none about packets being received. When you've got the right NIC and gmond on other nodes are sending packets, you'll also see notices of packets being received. You should know which NIC that you want the gmond packets to go out, so set this now.
If gmond is working properly, you should have 8 copies of gmond in the ps table. This node is ready to exchange information with other monitoring nodes. Leave /etc/gmond.conf for now.
Here's netstat output for a monitored machine (realserver) running gmond
realserver1:/src/mrtg/ganglia/ganglia-monitor-core-2.5.6# netstat -a | grep gm tcp 0 0 *:gmond *:* LISTEN udp 0 0 realserver1:32819 gmond_mcast:gmond ESTABLISHED udp 0 0 gmond_mcast:gmond *:* realserver1:/src/mrtg/ganglia/ganglia-monitor-core-2.5.6# netstat -an | grep 86 tcp 0 0 0.0.0.0:8649 0.0.0.0:* LISTEN udp 0 0 192.168.1.9:32819 239.2.11.71:8649 ESTABLISHED udp 0 0 239.2.11.71:8649 0.0.0.0:*
Not knowing much about multicast, I was surprised to find an IP:port in the output of netstat when the IP (239.2.11.71) was not configured on a NIC. The Multicast over TCP/IP HOWTO (http://www.ibiblio.org/pub/Linux/docs/HOWTO/other-formats/html_single/Multicast-HOWTO.html) only discusses multicast which needs to be routed (e.g. MBONE) and so all multicast IPs involved must be configured on NICs. Here's an explanation by Alexandre, who wrote Keepalived, which uses multicast in a similar fashion.
Alexandre Cassen Alexandre (dot) Cassen (at) wanadoo (dot) fr 11 Apr 2004
In mcast fashion, Class D address is not configured to NIC. you just join or leave the Class D, so called the mcast group. For mcast you can consider 2 differents design, most of common applications using multicast are done over UDP, but you can also create your own mcast protocol as VRRP or HSRP does, that way you are using mcast at same layer as UDP without adding UDP overhead. Since mcast is not connection oriented the both design UDP or pure RAW protocol are allowed. This contrast with the new SCTP protocol which add retransmission and connection oriented design in a one-to-many design (called associations).
So in mcast you must distinguish the sending and the receiving source. if using the UDP transport then you can bind sending/receiving points to special IP. On RAW fashion, you bind directly to device. Keepalived/VRRP operate at RAW implementing its own protocol, use a pair of sending/receiving socket on each interface VRRP instances run.
machine with GUI:
You should have apache/php4 installed.
Compile/install rrdtool using all defaults (files will go in /usr/local/rrdtool-x.x.x/). Link rrdtool-x.x.x to rrdtool (so you can access rrdtool files from /usr/local/rrdtool/). Unless you want to do a custom configure for ganglia-monitor-core, also copy librrd.a to /usr/lib/ and rrd.h to /usr/include/ (as you did for the gmond nodes).
Copy all the files from gmetad-webfrontend to DocumentRoot/ganglia/. Then mkdir DocumentRoot/ganglia/rrds/, the directory for the rrd database files. Edit DocumentRoot/ganglia/conf.php - some of the entries weren't obvious - here's some of my file:
$gmetad_root = "/usr/local/etc/httpd/htdocs/ganglia/"; $rrds = "$gmetad_root/rrds"; define("RRDTOOL", "/usr/local/rrdtool/bin/rrdtool");Add gmetad to the ganglia-monitor-core install by doing ./configure --with-gmetad; make; make install. You will get an extra file /usr/sbin/gmetad. Install gmetad/gmetad.initd as the init file and gmetad/gmetad.conf in /etc/.
Start up gmetad when you should see 8 copies in the ps table. My install worked fine (after a bit of iterative fiddling with the conf files), so I don't know what you do if it doesn't work.
By now the conf files need some attention and some of the entries in the two conf files must match up.
match "name" in gmond.conf with "data_source" in gmetad.conf (e.g. "Bobs LVS cluster").
This string will be used as the name of a directory to store the rrd files, so don't put any fancy characters in here (like an apostrophe) - blanks in a directory name are already hard enough to deal with.
"location": is a 3-D array to order the nodes for presentation in the "Physical View" page (a 3-D array is required for large clusters, where machines are located in 3-D, rather than in a single rack).
If you don't specify location, then "Physical View" will give you its own reasonable view - a vertical stack of boxes summarising each node.
If you do specify location, then each machine will be put in a Rack according to the first number. Machines with values 0,x,y, will be listed as being in "Rack 0"; machines with 1,x,y will be listed in Rack 1 etc.
The second dimension in the array determines the vertical position that ganglia puts the node in the rack. You can number the nodes according to their physical location (I have two beowulf master nodes in the middle of the rack, with 8 compute nodes above and 8 compute nodes below them), or logical location (the two directors can be on the top of the rack, with realservers below). You could have your directors in Rack 0, and your realservers in Rack 1.
Nodes with higher number location will be placed on the "Physical View" page above nodes with lower numbers. Location 1,0,0 will be at the bottom of Rack 1, while location 1,15,0 will be above it. If you thought node 0 was going to be at the top of a Rack, then you're sadly mistaken (this order must be a Northerm hemispherism). Presumably there is some connection between location and num_nodes, but I haven't figured it out and in some cases I've left the default value of num_nodes and in some cases I've put num_nodes=32 (larger than the actual number of nodes, in case of expansion).
Only having a 1-D LVS, I didn't use the 3rd dimension (left it as 0).
If two machines are given the the same location, then only one of them will display in the summary on the "Physical View" page.
trusted_hosts are only for data transfers between gmetad nodes (I think) - leave them as defaults.
rrd_rootdir (which I set to DocumentRoot:/ganglia/rrds/) and setuid must match or gmetad will exit with error messages telling you to fix it.
restart gmetad and gmond (if they haven't been cleanly restarted yet).
Here's netstat output for a machine GUI machine running both gmond and gmetad immediately after starting up the demons. (The connections between localhost:highport and localhost:gmond come and go).
director:/src/mrtg/ganglia/ganglia-monitor-core-2.5.6# netstat -a | grep gm tcp 0 0 *:gmond *:* LISTEN tcp 0 0 *:gmetad_xml *:* LISTEN tcp 0 0 *:gmetad_int *:* LISTEN tcp 0 0 localhost.mack.ne:gmond localhost.mack.ne:33287 FIN_WAIT2 tcp 0 0 localhost.mack.ne:33287 localhost.mack.ne:gmond CLOSE_WAIT udp 0 0 director.mack.net:32819 gmond_mcast:gmond ESTABLISHED udp 0 0 gmond_mcast:gmond *:* director:/src/mrtg/ganglia/ganglia-monitor-core-2.5.6# netstat -an | grep 86 tcp 0 0 0.0.0.0:8649 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8651 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8652 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:8649 127.0.0.1:33287 FIN_WAIT2 tcp 0 0 127.0.0.1:33287 127.0.0.1:8649 CLOSE_WAIT udp 0 0 192.168.1.3:32819 239.2.11.71:8649 ESTABLISHED udp 0 0 239.2.11.71:8649 0.0.0.0:*
surf to http:/my_url/ganglia. You should see a page with graphs of activity for your nodes. If you want the current information you have to Shift-reload, unlike with lvs-rrd, where the screen will automatically fresh every 5 mins or so. Presumably you can fiddle the ganglia code to accomplish this too (but I don't know where yet).
These images are to show that an LVS does balance the load (here number of connections) between the realservers.
Salvatore D. Tepedino sal (at) tepedino (dot) org 25 Mar 2004.
Figure 3. LVS with 2 realservers, serving httpd, single day.
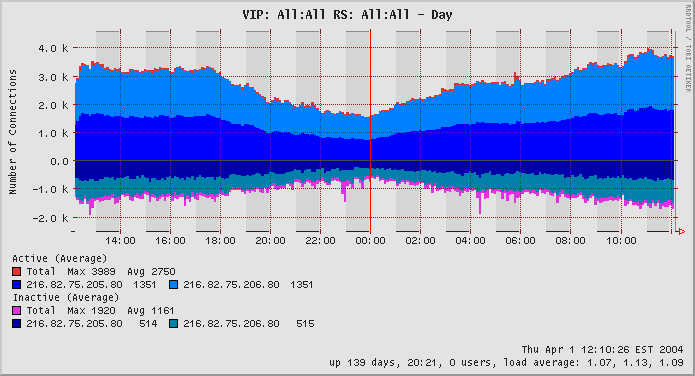
More images are at Salvatore's lvs-rrd website (http://www.tepedino.org/lvs-rrd/).
To get this graph, first you'd need to run the update script (included in the package) to generate the rrd files and start collecting the data. After a little while you can run the graphing script which will see the rrd files and generate the graphs based off the data in them. The easiest way to use the script it to just extract it into the web root of your director (which I figured that alot of people have as ultimate failovers if all their realservers go down), put in the cron tab (explained in the docs) wait a few minutes, then go to the index.php page and you should see the beginnings of a graph. The longer you let it (the cron job) run, the more data you've collected, the more data in your graphs. You don't need to know how to use RRD to use my script. The 'All: All RS: All:All' in the script just means "All VIPs:All Ports; RS: All Real servers: All ports". With the script you can select if you want to graph just connections to a specific VIP or RS, or VIP port or RS port, or any combination. Useful for large clusters.
My script generates the rrd line necessary to generate the graphs (tepedino.org/lvs-rrd). If you run it in verbose mode, it will spit out the rrd command line it uses to generate the graphs. If you like, I can give you some help with RRD. It's not the most obvious thing in the world to learn, but I had a lot of time on my hands when I decided to learn it, so I got fairly decent at it.
Figure 4. LVS with 2 realservers, serving httpd, week, showing realserver failure.
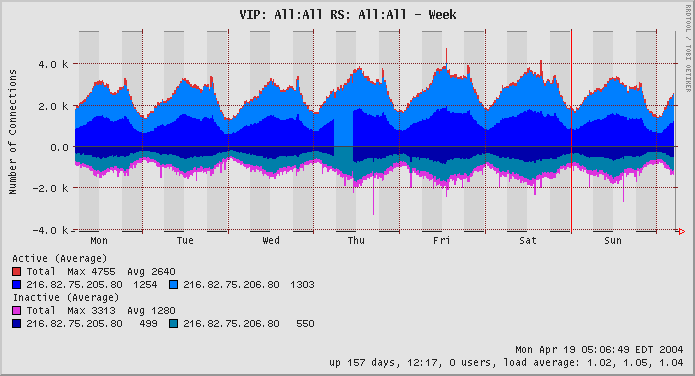
Note the failure of realserver 216.82.75.205, between 0600-1200 on thursday, with the other realserver picking up the load.
Malcolm Turnbull malcolm (at) loadbalancer (dot) org 27 Mar 2004.
Figure 5. LVS with 4 realservers, serving httpd, single day.
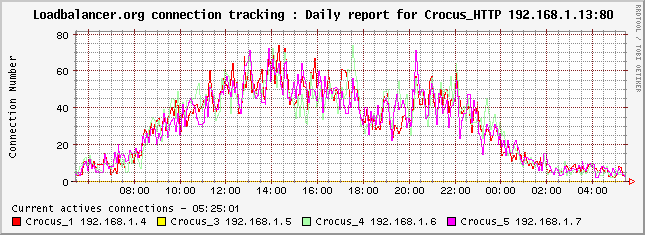
More images are available at loadbalancer.org (http://www.loadbalancer.org/lbadmin/stats/chart.php).
Karl Kopper karl (at) gardengrown (dot) org 2 Apr 2004
Here is an LVS serving telnet. The clients connect through to the realservers where they run their applications. Although the number of connections is balanced, the load on each realserver can be quite different. Here's the ipvsadm output taken at the end of the time period shown.
# ipvsadm -L -t 172.24.150.90:23 Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP cluster:23 wrr -> clnode7:23 Route 1 53 1 -> clnode8:23 Route 1 38 0 -> clnode2:23 Route 1 46 1 -> clnode10:23 Route 1 49 0 -> clnode9:23 Route 1 49 0 -> clnode6:23 Route 1 35 1 -> clnode5:23 Route 1 33 0 -> clnode4:23 Route 1 36 0 -> clnode3:23 Route 1 40 0 -> clnode1:23 Local 1 42 0
Figure 6. LVS with 10 realservers, serving telnet, load average for past hour, images of total cluster.
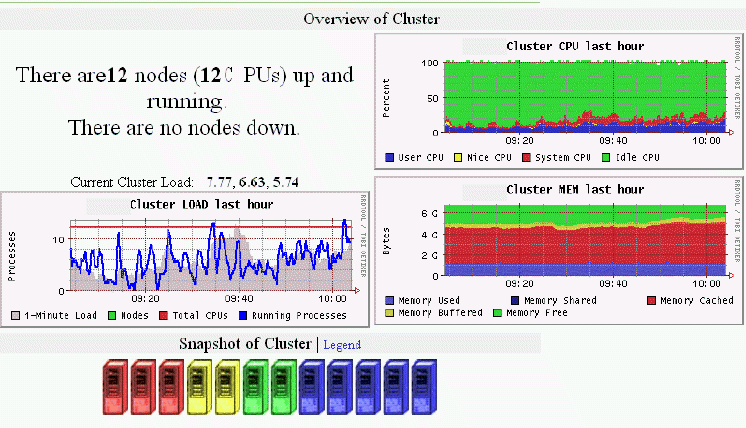
The graphs above show total one minute load average for the LVS cluster. When the load average on any individual box is greater than 1 (for uniprocessor systems) the icon for the realserver (the boxes at the bottom of the image) turns red.
Figure 7. LVS with 10 realservers, serving telnet, load average for past hour, for each realserver and the cluster manager.
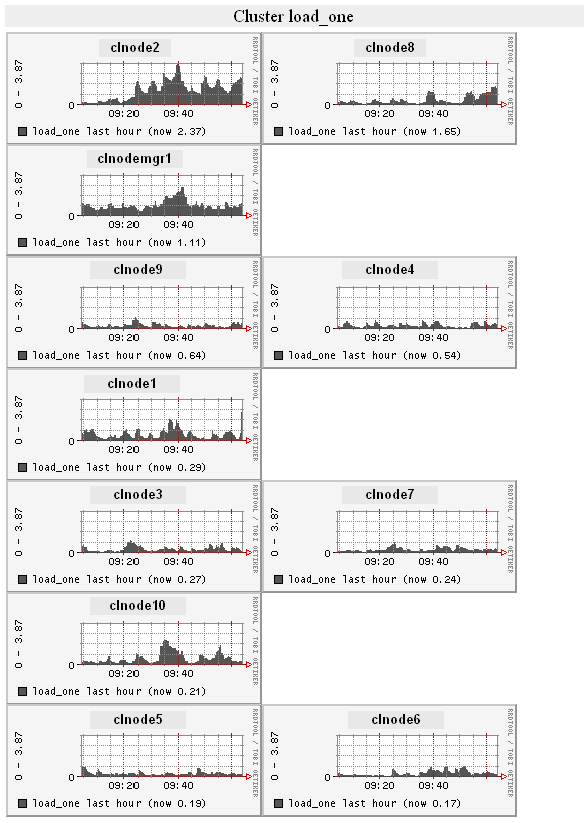
The graphs above show the bottom-half of the Ganglia web page with the one minute load average (for each realserver) for the past hour. Note that the load average is quite different for each realserver. Also shown is the cluster node manager (outside the LVS), used by the realservers for authentication and print spooling.
Magnus Nordseth magnus (at) ntnu (dot) no 05 Apr 2004
Figure 8. LVS with 3 quad processor realservers, serving https, single day, y-axis is cpu-idle (all idle = 400%).
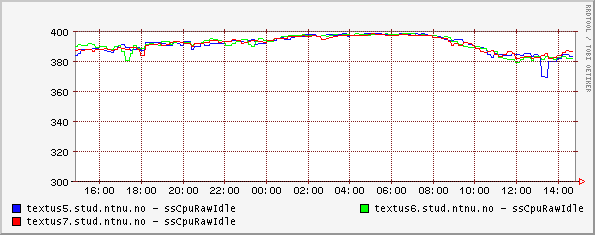
The graph shows cpu-idle for three identical realservers running https. Each realserver has 4 cpu's, thus maximum idle cpu is 400%. The graph was created with in-house software.
Nagios is mentioned elsewhere in this HOWTO by various posters as a monitoring tool.
anon
I'm interested with LVS to do some load balancing with HTTP. I'm testing LVS with VMWare (i'm simulating two Windows 2003 real servers). Is there a way to do some load monitoring with windows realservers? I know the feedbackd project, but there's no win32 agent... If LVS cannot do Load monitoring I will use bigip or other proprietary solution that could handle load monitoring.
Peter Mueller pmueller (at) sidestep (dot) com 11 Jul 2005
You can try using the Nagios windows agents and some shell scripts to accomplish your goals. Two Nagios Windows programs that I am aware of are: http://nagios-wsc.sourceforge.net/ and http://nsclient.ready2run.nl/
Joe Sep 2011. The latest net-snmp-lvs-module from Robin Bowes robin (dot) bowes (at) yo61 (dot) com is
A MIB has been written for LVS by Romeo Benzoni rb (at) ssn (dot) tp (Nov 2001). It's available as
| Note |
|---|---|
| Joe: there's a 64 bit problem with the net-snmp-lvs module that's been fixed. Make sure you're using at least the 0.0.4-2 module. | |
- code and documentation (http://anakin.swiss-support.net/~romeo/lvs-snmp/). The latest (Mar 2002) is at http://anakin.swiss-support.net/~romeo/lvs-snmp/ucd-snmp-lvs-module-0.0.2.tar.bz2 (Joe: this seems to have disappeared).
- (Joe: incase other links go dead): net-snmp-lvs-module-0.0.4.tar.gz, net-snmp-lvs-module-0.0.4-1.EL4.src.rpm, net-snmp-lvs-module-0.0.4-2.EL4.src.rpm
- Malcolm Turnbull's download/SNMP (this directory includes net-snmp-5.3.0.1.tar.gz)
-
Jack Neely (who provided the updates):
net-snmp-lvs-module-0.0.4-1.EL4.src.rpm, and the updated version
net-snmp-lvs-module-0.0.4-2.EL4.src.rpm
(http://install.linux.ncsu.edu/pub/yum/CLS/CLSTools.EL4/srpms/net-snmp-lvs-module-0.0.4-2.EL4.src.rpm).
Laurentiu C. Badea (L.C.) lc (at) waat (dot) com 26 Dec 2008
The new version is in the 4-2 src rpm (for reference it's at http://archive.linuxvirtualserver.org/html/lvs-users/2008-10/msg00011.html). I have been using it with cacti for... well, since then.
The source rpm says EL4 but it should compile on many rpm-based distros with "rpmbuild -bb $src.rpm". You can make a source tar.gz by running "rpmbuild -bp $src.rpm" and then archiving the prepared sources from where they were unpacked.
Though, essentially, the "source" is the original net-snmp-lvs-module-0.0.4.tar.gz found in the HOWTO somewhere. The src rpm packages it with the ipvsadm sources plus a few patches and automates the patch, build and install procedure.
from 4-1 to 4-2. This is the list of files in 4-2:
COPYING ipvsadm-1.24-kernhdr-1.2.1.patch ipvsadm-1.24.tar.gz lvs-counter64.patch net-snmp-lvs-module-0.0.4-2.6-kernel.patch net-snmp-lvs-module-0.0.4-kernheaders.patch net-snmp-lvs-module-0.0.4.tar.gz net-snmp-lvs-module.spec
Jack Neely jjneely (at) ncsu (dot) edu 1 Oct 2008
I've setup net-snmp-lvs in an attempt to move the monitoring of my lvs/keepalived balancer into Cacti. I've gotten most things working and even have an RPM that folks might be interested in. I've built this on RHEL4 and 5 i386 (I believe it needs a bit of extra work for 64 bit arches.) http://install.linux.ncsu.edu/pub/yum/CLS/CLSTools.EL4/srpms/net-snmp-lvs-module-0.0.4-1.EL4.src.rpm
The values provided for the lvsServiceStatsInBytes attributes are not right. They don't seem to be bits or bytes. Cacti is graphing out my ssh service as doing terabytes of traffic per second. Running snmpwalk ; sleep 2 ; snmpwalk gives me the following:
Running ipvsadm -L --stats for the same firewall mark prints out the in bytes service counter at 9737M.
Laurentiu C. Badea (L.C.) lc (at) waat (dot) com 02 Oct 2008
I'm not sure why it's like this, but you just need to swap the two 32-bit fields around to get to the real value (which incidentally is the same as shifting >>32 when they are all zeroes).
Take for example 2670058611031409148 returned by SNMP for 2182G. In hex (easier to work with than binary) it is 250df429 000001fc, the real value is 000001fc 250df429 which is 2182465057833 or 2182G.
I just used the rates instead for the time being (just remember to change from COUNTER to GAUGE so cacti knows how it works).
I was looking at this last night. The problem was that ASN_COUNTER64 expects a "struct counter64" and is given a "long long" (__u64) instead. The attached patch should correct this problem.
Fix the bad values returned for the 64-bit byte counters.
--- lvs.c.orig 2006-01-02 14:31:54.000000000 +0000
+++ lvs.c 2008-10-03 18:43:48.000000000 +0000
@@ -131,6 +131,17 @@
}
}
+/** set a counter64 snmp response field from a __u64 value
+
+**/
+static
+void netsnmp_set_var_counter64_value(netsnmp_variable_list *var, __u64 *val){
+ struct counter64 val64;
+ val64.high = *val >> 32;
+ val64.low = *val & 0xffffffff;
+ snmp_set_var_typed_value(var, ASN_COUNTER64, (u_char *)&val64, sizeof(val64));
+}
+
/** returns the first data point within the lvsServiceTable table data.
Set the my_loop_context variable to the first data point structure
@@ -271,10 +282,10 @@
snmp_set_var_typed_value(var, ASN_COUNTER, (u_char *) &stats->outpkts, sizeof(stats->outpkts));
break;
case COLUMN_LVSSERVICESTATSINBYTES:
- snmp_set_var_typed_value(var, ASN_COUNTER64, (u_char *) &stats->inbytes, sizeof(stats->inbytes));
+ netsnmp_set_var_counter64_value(var, &stats->inbytes);
break;
case COLUMN_LVSSERVICESTATSOUTBYTES:
- snmp_set_var_typed_value(var, ASN_COUNTER64, (u_char *)&stats->outbytes, sizeof(stats->outbytes));
+ netsnmp_set_var_counter64_value(var, &stats->outbytes);
break;
case COLUMN_LVSSERVICERATECPS:
snmp_set_var_typed_value(var, ASN_GAUGE, (u_char *) &stats->cps, sizeof(stats->cps)); @@ -434,10 +445,10 @@
snmp_set_var_typed_value(var, ASN_COUNTER, (u_char *) &stats->outpkts, sizeof(stats->outpkts));
break;
case COLUMN_LVSREALSTATSINBYTES:
- snmp_set_var_typed_value(var, ASN_COUNTER64, (u_char *) &stats->inbytes, sizeof(stats->inbytes));
+ netsnmp_set_var_counter64_value(var, &stats->inbytes);
break;
case COLUMN_LVSREALSTATSOUTBYTES:
- snmp_set_var_typed_value(var, ASN_COUNTER64, (u_char *) &stats->outbytes, sizeof(stats->outbytes));
+ netsnmp_set_var_counter64_value(var, &stats->outbytes);
break;
case COLUMN_LVSREALRATECPS:
snmp_set_var_typed_value(var, ASN_GAUGE, (u_char *) &stats->cps, sizeof(stats->cps));
|
Jack
a src.rpm: net-snmp-lvs-module-0.0.4-2.EL4.src.rpm (http://install.linux.ncsu.edu/pub/yum/CLS/CLSTools.EL4/srpms/net-snmp-lvs-module-0.0.4-2.EL4.src.rpm)
Laurentiu
I would also create the necessary config and reload snmpd on install and uninstall, so it will "just work" immediately after install, something like this.
mkdir -p $RPM_BUILD_ROOT/etc/snmp echo "dlmod lvs /usr/lib/libnetsnmplvs.so" > $RPM_BUILD_ROOT/etc/snmp/snmpd.local.conf %files ... %config(noreplace) /etc/snmp/snmpd.local.conf %post test $1 = 1 && chkconfig snmpd && service snmpd reload || true; %postun test $1 = 0 && chkconfig snmpd && service snmpd reload || true; |
| Note |
|---|---|
| If you can't access the snmp information (get timeouts, or snmpwalk crashes) | |
Michael Moody michael (at) gsc (dot) cc 24 Sep 2008
Depending on distribution, check /var/log/messages for more info. I had a problem where snmpd was running as "other than root", preventing the libnetsnmplvs from being able to access the ipvs tables.
Laurentiu C. Badea (L.C.) lc (at) waat (dot) com 12 Dec 2008
Build the net-snmp-lvs-module rpm posted earlier and install it on your servers running snmpd, then you can access the LVS data via SNMP in cacti. You can whip up a quick graph using the snmp-oid template, or you can make a more elaborate graph template that can be attached to hosts.
For example, the OIDs you need for bandwidth per service are:
bytes in: 1.3.6.1.4.1.8225.4711.17.1.13.i bytes out: 1.3.6.1.4.1.8225.4711.17.1.14.i |
where "i" is the service index (1...number of LVS services defined). You can use snmpwalk to find all the fields.
Jack Neely jjneely (at) ncsu (dot) edu 17 Dec 2008
In a similar vain...I'm using Cacti to graph services based on firewall mark. When a fwmark is removed I tell Cacti to reindex the LVS SNMP data so each data source is still groking the right part of the SNMP tree. This does that...but (today at least) also edited the path to the RRD for each data source to use the previous data source's RRD. I then became unhappy as I watched Cacti trash all my pretty graphs.
How do other folks handle this case when a service disappears from LVS with Cacti?
Ratz
The file linux/snmp.h represents the SNMP RFCs. IPVS is not specified in an RFC, so adding this has no chance I believe.
If you want to generate your own MIB, use one of the reserved sub trees of the MIB DB for such projects and peruse m2c. If you really plan on writing one, get back to us so we can sort out the header to freeze the API.
The simple approach we've been using for years:
- Prepare the values through cronjobs by calling ipvsadm or parsing proc-fs and write SNMP type values (u32, u64, char ...) into single files e.g./var/run/lvs_snmp/VIP1_act_conns.out.
Configure snmpd.conf to read out those files using cat, e.g.
exec VIP1_act_conns /bin/cat /var/run/lvs_snmp/VIP1_act_conns.out
- Use snmpwalk and grep for VIP1_act_conns to get the OID and off you go monitoring those values.
- Repeat for all values you would like to poll.
If you need up to date values (not recommended though) you can also directly call shell scripts using the exec directive.
Joseph T. Duncan duncan (at) engr (dot) orst (dot) edu 21 Aug 2006
Presently I collect CPU, Memory in USE, and Network traffic statics from my windows terminal server "real servers" via snmp. I toss this information into an rrd database for making pretty graphs along with usage parsed from lvs stats. Finaly I take the CPU and Memory stats and use them to adjust my weight tables. My script duncan_main.pl for doing this is still in its infancy as I am getting stuff ready for this fall term, but it should be fun to see how it all works out. 28 Dec 2006: Here's an update lvs_weight.pl
Monitoring disks is not directly an LVS problem, however since disks are the most failure prone component of a computer, you need to have a plan to handle disk failure (I pre-emptively change out my disks at the end of their warrantee period, even if they're not giving problems).
Linux J. Jan 2004, p 74 has an article on the SMART tools for monitoring ATA and SCSI disks. Apparently for years now IDE and SCSI disks have been using the Self Monitoring, Analysis and Reporting Technology (SMART) standard to report low level errors (e.g. disk read errors, there's dozens of tests). This has been available in tools like Maxtor's PowerMax (for windows). (VAX's and Cray's continuously monitor and report disk errors - I've never known why this wasn't available on other machines.) The current SMARTv2 spec has been around since Apr 1996.
Apparently these SMART tools have been available on Linux for a while and run on mounted disks. The source code is at http://smartmontools.sourceforge.net/
There are two components,
- smartd which reads a config file and runs in background monitoring your disks and writing to syslogd (and/or e-mailing you)
- smartctl which runs various checks from the command line and which you can run as a cron job to do an exhaustive (1hr long) check (e.g. on Sun morning at 1am).
A lightweight and simple webbased cluster monitoring tool designed for beowulfs procstatd, the latest version was 1.3.4 (you'll have to look around on this page).