Copyright © 2007 Joseph Mack, released under GPL.v3
Software Freedom Day, UNC, Chapel Hill, NC, 14 Sep 2007
Table of Contents
Figure 1. LVS Logo
 |
LVS logo.
The Linux Virtual Server (LVS) is kernel code, which turns a GNU/Linux box into a tcpip load-balancer (director). A director is a router with slightly funny rules. The director sits in front of a bunch of identical servers and makes them appear as a single failure-proof server, whose capacity is the sum of all the servers.
Figure 2. LVS Overview
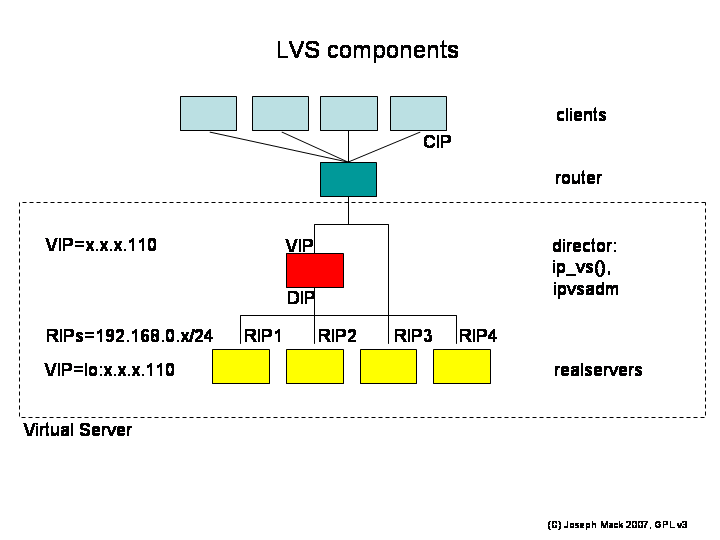 |
LVS Overview
LVS code runs on the director and consists of
- kernel code (ip_vs)
- a userland configuration utility (ipvsadm).
LVS project was started in 1999 by Wensong Zhang, a student in China.
Current LVS teams members
- Julian Anastasov (Bulgaria)
- Graeme Fowler (England)
- Simon Horman (Australian working in Japan)
- Joseph Mack (Australian working in USA)
- Roberto Nibali (Sicilian working in Switzerland)
Richard Stallman
I'd also like to thank Richard Stallman, for without him we wouldn't have free software, like the GNU tools and Linux.
better performance/throughput/reliability for a fixed cost.
When you put up a server, you want to maximise your performance, and your uptime. Performance is glamourous and while everyone likes having the biggest machine on the block, uptime is the real clincher - you loose money or goodwill if your machine goes down.
- What everyone wanted: performance
- What everyone needed: 100% uptime (you hide failure/planned maintenance)
Let's look at reliability/uptime first.
In the early days, a large server machine, from Sun or SGI, was expensive (e.g. 50k$). The obvious solution to handling downtime was to buy another 50k$ server and bring it up when you needed to bring down the first server. The bean counters didn't like this, as half of your machinery (50k$) was off or idle except for an hour or two a year. They wanted both servers running all the time, but didn't like hearing that if you did this, you could only run them at half capacity.
Figure 3. Single Big Server
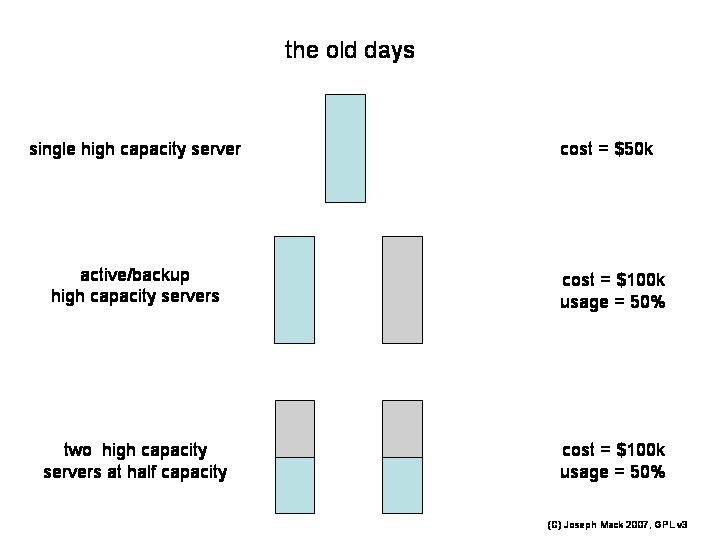 |
Single Big Server
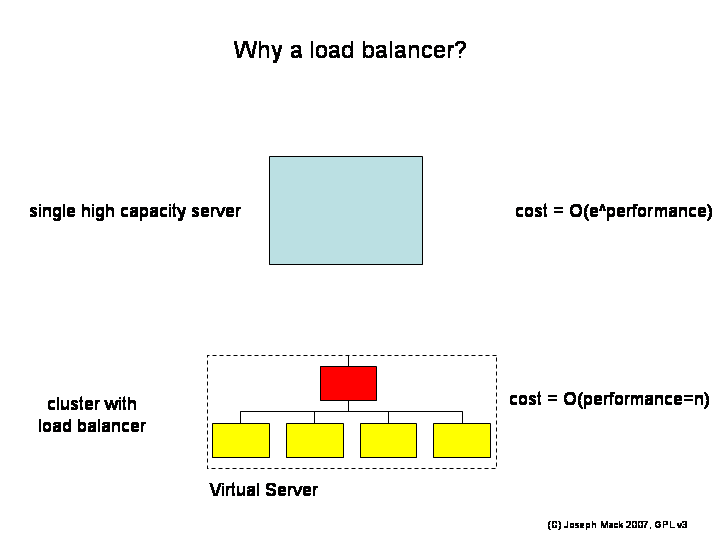
The solution was to replace the expensive servers with a rack of cheap and unreliable, lower performance commodity PC-grade servers and put a load-balancer in front of them. Sure you needed 10 PC's, where previously you had a single large server, but now when you removed one box for routine maintenance, only 10% of your hardware was off-line and the bean counters were OK with this.
Figure 4. Load Balanced Server
 |
Load Balanced Server
There was another win: With a single server, if you wanted more performance, cost=O(e^performance). With the load balancer, for the same money you got about the same performance (only with more boxes), but now cost=O(performance). This feature allowed you to rapidly reconfigure your virtual server. If you had a big news event, or Rolling Stones tickets were going on sale next morning, you plugged in a few more servers for the time needed and then took them away when the event was over.
- from single box: cost=O(e^performance)
- from array of boxes: cost=O(number_boxes)=O(performance)
There was only one problem: the load balancer version is more complex. You need to monitor unreliable hardware, and setup and run the machine. However you only setup once and the costs are amortised over the life of the machine.
Because of the linear scaling of cost with performance, for sufficiently large throughput, everyone turns to clusters of computers.
LVS was originally built around the masquerading code of the 2.0 kernels. It was rewritten for the netfilter code of the 2.4 kernels. While the code has been remarkably bug-free, with the wisdom of 8 yrs of hindsite, it's time to rewrite the code once again. Unfortunately without anyone working even near fulltime on LVS, we're having trouble keeping up with reasonable requests for features from users, and can't contemplate rewriting the whole project.
It would be nice if LVS had been written in a logical order i.e. what was needed next. Instead the code that was written was what someone wanted to do or could do. There are things that we'd like LVS to do, that it can't, because no-one wrote it. For some functionalities (e.g. failover), we have multiple sets of code, which do the same thing. That's life in Free Software.
Here are the names of the LVS components.
- CIP: client's IP
- VIP: Virtual IP (on director and realservers)
- DIP: director's IP in the RIP network (default route for LVS-NAT, and is moved on director failover)
- RIP (RIP network): realserver's IP
Figure 5. LVS nomenclature
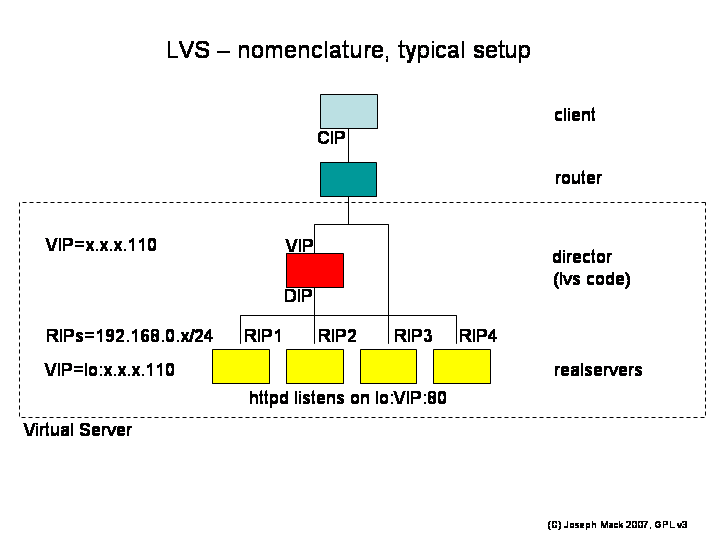 |
LVS Nomenclature (example shows virtual service on port 80)
The word "virtual" give LVS a non-obvious nomenclature.
On being "virtual"
virtual: from Merriam-Webster
"being on, or simulated on a computer or computer network"
since a computer is Turing complete, you can do anything computable, so you can have virtual memory, virtual disks, virtual ethernet cards, virtual reality, even a virtual computer. You can use a computer to make a virtual anything. Using the word "virtual" to describe the function of a computer, or cluster of computers, then is a NOOP.
- virtual server:
a single computer offers a service. An assembly of computers, which to the outside world is a virtual computer offering a service, is called a virtual server.
- realserver:
The servers behind the director, which terminate the tcpip connection from the client, and which offer the service.
The name "Linux Virtual Server" occupies a large fraction of name space. After the fact, I talked to Maddog (the Director of Linux International) at OLS. He said that we could have used "Bob's Linux Virtual Server" or "Fred's Linux Virtual Server" but we should not have taken the whole name space.
With another type of virtualisation (Xen, QEMU, Linux-VServer and OpenVZ) being developed, we should expect more name space clashes.
Here's a typical LVS setup. Since LVS is often used to load balance webservers, all the examples in this talk assume a farm of loadbalanced webservers.
Points to note are
- The director has the VIP, but no service is listening on director:VIP:80 and thus the director would normally not accept a packet to VIP:80. The service instead is listening on each of the realservers at VIP:80.
- There are no connections terminating or originating on the director. On the director, netstat doesn't show any connections from the CIP to the VIP.
-
The router only knows about the VIP on the director (we'll talk later about why this is)
and routes packets for the VIP to the director.
With the VIPs on the realservers to provide clues for the router, we shouldn't need the VIP on the director. The requirement for the VIP on the director is a holdover from the original design. The VIP lets the router know where to send the packets. As well there is a hook into the routing table for LVS allowing it to capture packets with dest_addr=VIP. These requirements can be bypassed with the current code, but it's an ungraceful kludge. We'd like to rewrite LVS so that there is no longer a requirement for the VIP on the director.
- The director forwards packets much like a router, but uses different rules than a router. The forwarding process breaks the server end of the tcpip connection into two parts - the director accepts the packet and the realserver replies.
- Since the client could be directed to any realserver, the realserver must present identical content.
- On the realserver, the route for packets VIP:80->0/0 is via the router. (the return route is NOT through the director.)
There's 3 different ways the director can forward packets; LVS-NAT, LVS-DR (which I'll show you) and LVS-Tun.
Table 1. Packet path in LVS-DR connecting to VIP:80
| network segment | packet type | packet addressing |
|---|---|---|
| client->director | IP | CIP:1025->VIP:80 |
| director->realserver | ethernet (content = IP packet) | (MAC DIP)->(MAC RIP1)[CIP:1025->VIP:80] |
| realserver->client | IP | VIP:80->CIP:1025 |
1st hop: The first packet hop CIP:1025->VIP:80 arrives at the director, where there is no service listening on port 80. Normally the director would return an icmp "connection refused" message. However LVS has hooked into the director's tcpip routing and accepts the packet.
Figure 6. LVS-DR 1st hop
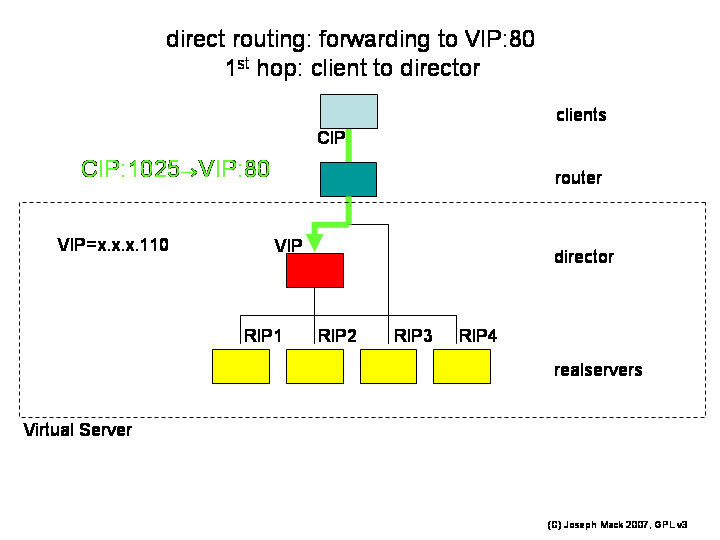 |
LVS-DR 1st hop
2nd hop: Let's assume that this packet is the first in the connection from the CIP:
Figure 7. LVS-DR 2nd hop
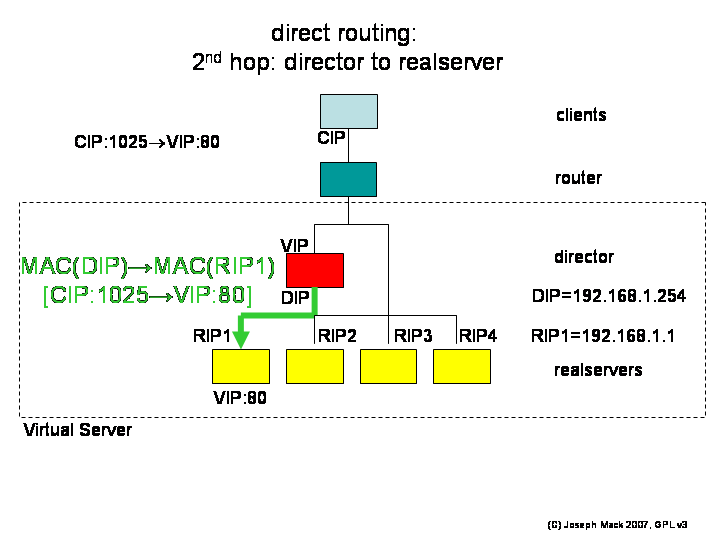 |
LVS-DR 2nd hop
- the director looks up its connection table, finds no entry for CIP:1025->VIP:80, creates a new entry,
- looks up pool of available realservers and let's say it assigns the connection to realserver_1; now any further packets from the CIP:1025->VIP:80 will go to realserver_1.
The packet is still on the director. You can't send a packet with dest_addr=VIP, from of a machine that has the VIP - the routing would have already determined that the packet be delivered locally. What we want is for the packet to be forwarded to the selected realserver. LVS handles this problem by leaving the IP addressing of the packet unchanged, and constructing an ethernet packet with in the destination MAC address of the selected realserver. The packet is put in the output queue, and the realserver, having the correct MAC address picks up the packet.
The ethernet packet arrives at the realserver, which has a service listening on VIP:80. The packet is delivered locally.
3rd hop: The reply packet VIP:80->CIP:1025 is routed through the router (not the director), and delivered to the client.
Figure 8. LVS-DR 3rd hop
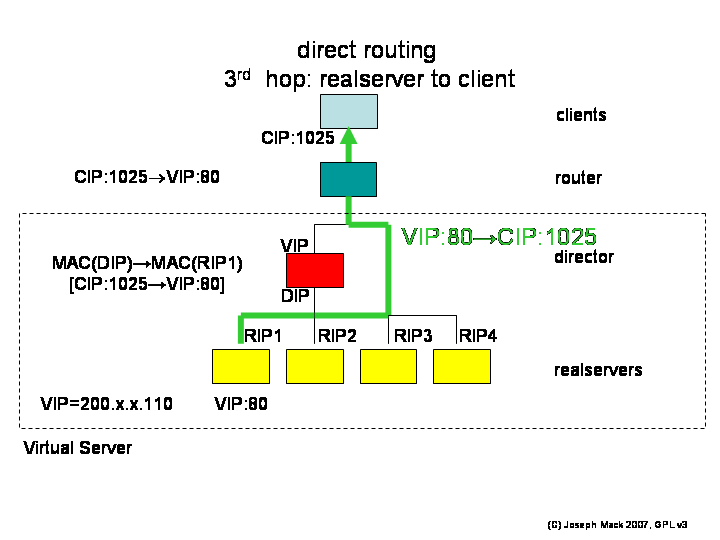 |
LVS-DR 3rd hop
Client/Server semantics are preserved
- The client sends its packets to VIP:80 and receives a reply from VIP:80
- the client thinks it is connecting directly to a server
- the realserver thinks it is being contacted directly by the client
neither the client nor the realserver can tell that the director was part of the packet exchange.
The director keeps a list of current connections (which client is connected to which realserver) and statistics on connections to each realserver. The director, in order to load balance, has to keep the realservers approximately equally loaded. The process of deciding which realserver receives a new connection is called scheduling. The optimum scheduling algorithm depends on the service being forwarded.
Since you don't know which realserver a client will be connected to, the content served by the realservers must be identical.
-
round robin: (default)
The scheduler picks the next realserver in the list. Let's say the LVS has 4 realservers and you request a webpage with 5 gifs. The client will fetch the webpage, and after parsing it, will request 5 more hits (total 6 fetches).
Figure 9. LVS scheduling - Round Robin
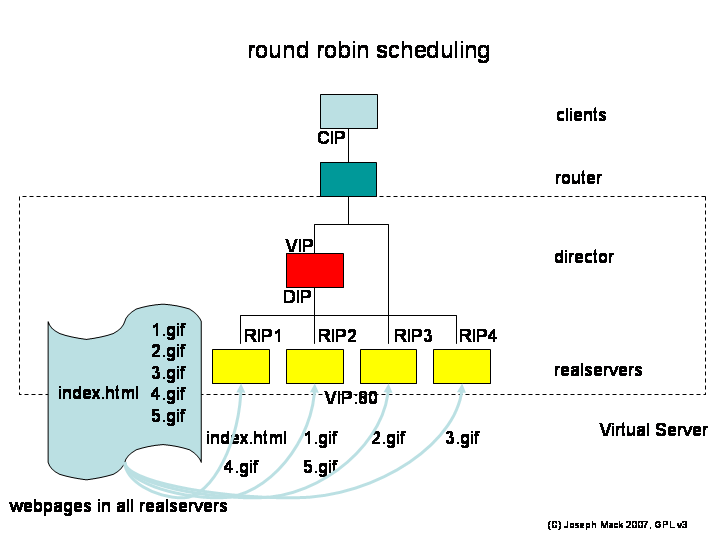
LVS scheduling - Round Robin
If you're the only one on the system, the html page will be fetched from realserver_1, and the subsequent 5 gifs will be served by realserver_2, realserver_3, realserver_4, realserver_1 and realserver_2. Your 5 gifs will be served in parallel by 4 servers. In practice you won't notice the speedup, as the latency through the internet will be higher than the latency reading from disk or the realserver's memory.
-
least connected:
The scheduler picks the realserver with the least number of connections. This is not the same thing as the least loaded, but hopefully it's close. This would seem to be the obvious default scheduler. However if you bring a new realserver on-line (say after maintenance), it initially has no connections and will be swamped when it gets all the new connections (the thundering herd problem). RR seems to work well enough.
-
DH (destination handler)
The first largescale use of LVS was for caching webservers (i.e. squids). After a squid retrieves a URL, the content is cached and subsequent fetches will be from the squid and not the internet. If your LVS is a squid farm, you'd like your request to be sent to the squid cacheing that URL. The scheduler works by looking at the requested website_name (excluding directories, filenames), hashes it (modulo the number of squids) and sends the request off to that squid. Requests for pages from a particular website will always go to the same squid, whether it has those pages already cached or not.
Figure 10. LVS scheduling - Destination Handler
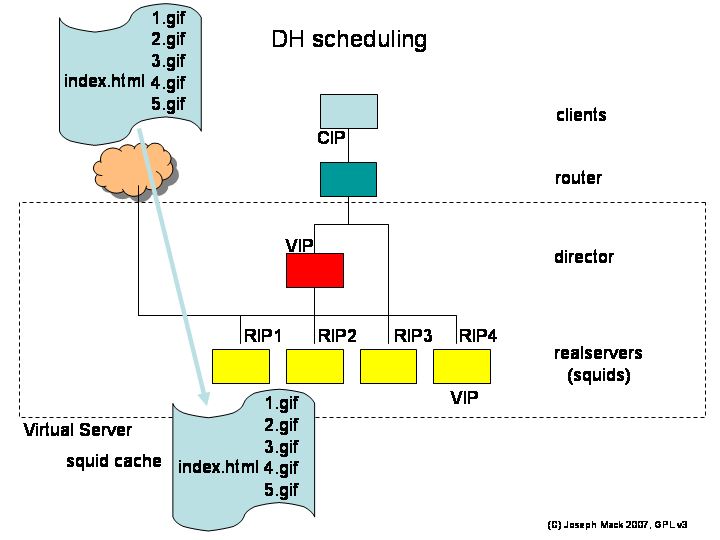
LVS scheduling - Destination Handler
Let's say the realservers now are squids, rather than webservers. Now what happens when the client fetches the webpage with 5 gifs, which in this scenerio is on a webserver out on the internet?
- client requests URL:/index.html; the director hashes the website_name and assigns the connection to say squid_1; squid_1 fetches URL:/index.html, stores it and sends a copy to the client.
- for the 5 gifs, the director requests them from squid_1, which has been assigned to cache that URL. squid_1 doesn't have the gifs, so it fetches and stores them and passes copies to the client.
Those files are now in the cache of squid_1. When another client connects to the LVS and requests the same URL, the files will be now fetched directly from the squid.
The content stored by each squid will be different. This isn't a problem until you have to failout one of the realservers. You'll have a new hash function and now URLs may or may not be on the expected squid. Eventually the squid caches will fill again and the old entries, now sitting on the wrong realserver, will expire.
-
SH (source handler)
Normal webpages are read-only. If instead the client needs to write to the realservers (e.g. shopping cart, database), you use the -SH scheduler, which sends all the connections for a session from a particular client to the same realserver. After the client disconnects, scripts external to LVS replicate the saved data to the rest of the realservers. The -SH scheduler has a timeout, set to the time by which you expect the written data to be replicated to the other realservers: if the client reconnects within the timeout, you reconnect them to the original realserver; if they connect after the timeout, they're allowed to connect to any realserver.
Figure 11. LVS scheduling - Source Handler
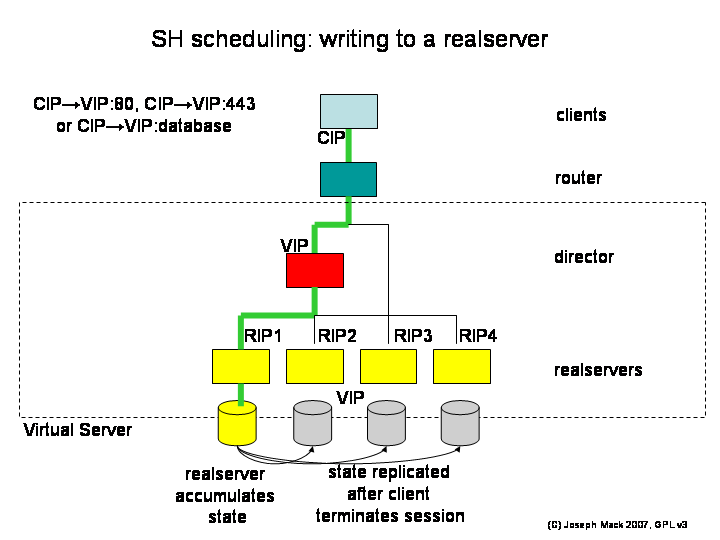
LVS scheduling - Source Handler
The content of the realservers is the same at the beginning of the connection. During the connection, one of the realservers accumulates state, and then when the connection terminates, the state is replicated to the other realservers, making all realservers identical again.
All machines (director, realservers) have the VIP and all VIPs can be seen by the router. How does the router know to send the packets from the client to the director and not to the realservers?
Figure 12. LVS arp problem
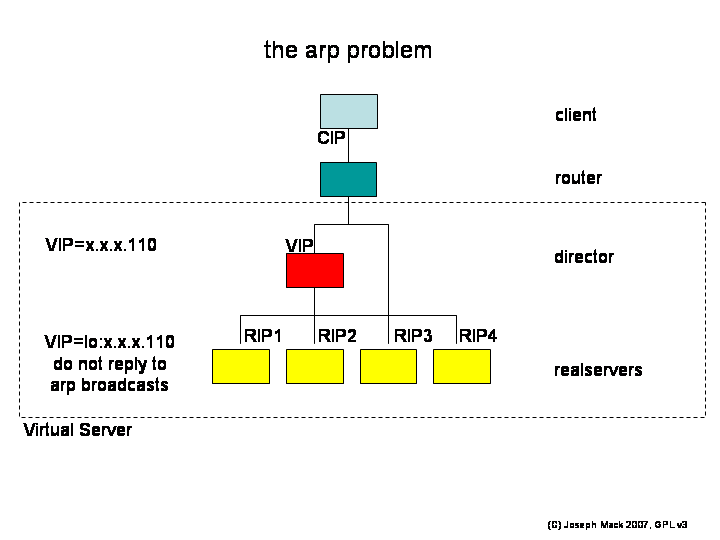 |
LVS arp problem
Mapping between hardware (MAC) address and IPs is done by arp (address resolution protocol). Initially the router doesn't know which (if any) machines have the VIP, so it puts out a broadcast message "who has VIP, tell router". Normally only one machine will have the VIP and that machine will reply. When you have multiple machines with the VIP and you want only the director to get packets for the VIP, you tell the realservers not to reply to arp requests for the VIP. When the router says "who has IP=VIP" only the director replies.
With most other unices, doing this is trivial - you set the -noarp flag for the VIP on the realservers. However for the Linux kernels >=2.2, Linux no longer honours the -noarp flag. Quite why this is a good idea has not been explained - supposedly it's a feature. But this being Linux, we have the source code, and over the years the LVS team has written several different lots of code to get around the problem, all of which required you to patch the realserver kernels (a pain). But with Linux-2.6, the noarp functionality from one of the LVS patches, is again in the standard kernel and has been backported to the 2.4 kernels. So after 5 years without it, Linux again has the the -noarp functionality, but you get it through an arcane set of switches in the kernel, rather than from the command line. Such is progress.
Handling the arp problem turns a trivial installation into a major production. If you haven't handled the arp problem, connections from the client will go directly to whichever machine just happens to have its VIP in the router's arp cache. If it's the director, the LVS will work perfectly and you'll think you're an LVS whiz. If it's one of the realservers, all your replies will come from that one realserver and you'll get no loadbalancing. If the location of the VIP bounces around in the router's arp cache, your client's session will hang or get tcpip resets.
Even if you haven't solved the arp problem, the LVS can appear to work (for some definition of "appear").
Machines of course fail or need planned maintenance. You just hide the downtime with redundancy.
The code to handle failure runs on the director in userland and is separate from the ip_vs() code, which does the forwarding and scheduling.
The director has available several independant sets of tools, to automatically reconfigure the LVS on-the-fly in response to changing load, or node failure.
The failover and reconfiguration demons send commands to ipvsadm.
- mon
- ldirectord (Linux-HA)
- keepalived (vrrp)
Figure 13. LVS realserver failover
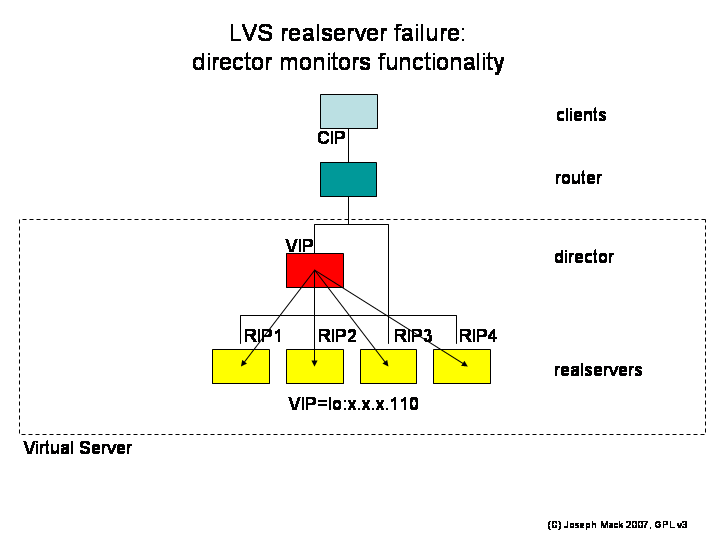 |
LVS realserver failover
- planned maintenance: set the weight=0 for that service/node. This will stop any new connections being assigned to that service/realserver. You then wait for the number of connections to drop to zero and then bring down the service/realserver.
failure (unplanned maintenance): use healthchecking - continuously
- test service on each realserver:VIP:80 from the director,
- test network connectivity
On failure, you remove the service/node from the director's LVS connection table. If realserver failure occurs in the middle of a client's session, the session is lost. This isn't always a problem: For httpd the client's connection will timeout, or they'll click again and be connected to a new realserver, without realising that the original machine failed. However if you're in the middle of a terminal session, you're hosed - let's hope you've saved your data.
For convenience, until now, I've only shown one director. For production you'll have two; active and standby.
Figure 14. LVS director failover
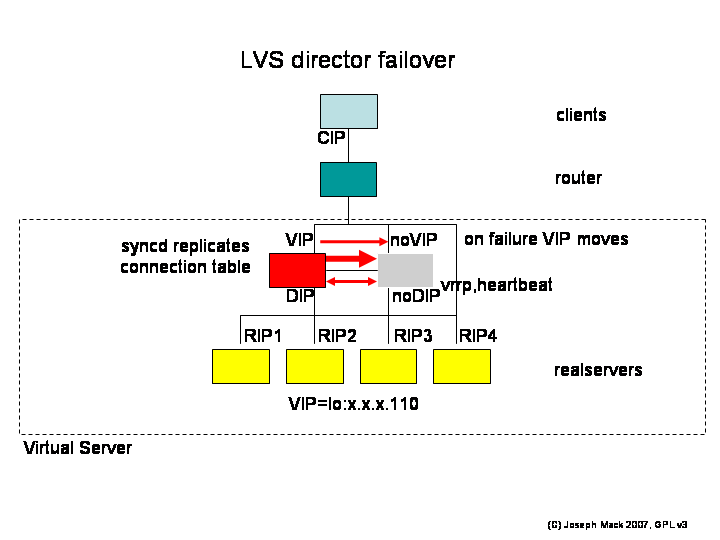 |
LVS director failover
Directors
- monitor each other's health
- standby director updates the LVS connection table by listening for broadcasts from the active director.
Normally there are two directors, active and stand-by, which test each other for functionality (heartbeat, vrrp, ping).
The active director has its table of connections, which it broadcasts via a syncd. The stand-by director updates its connection table from these broadcasts. The stand-by director has ip_vs() running, but since it doesn't have the VIP, it's not receiving any packets for the VIP and doesn't ever get to look up its connection table. On failover, the stand-by director assumes the VIP and automatically begins receiving packets for the VIP, including for ESTABLISHED connections, which were originally handled by the other director. The packets being for the VIP, the new active director looks up the LVS connection table and forwards these packets, thereupon becoming the active director. The new active director starts broadcasting its updated connection table (and the old active director becomes the back-up director by relinquishing the VIP and listening for syncd broadcasts).
In the early days (before we'd done the measurements) people would ask us how many realservers a particular piece of director hardware, would support, for a particular service (e.g. a webserver farm, database).
If we had to do tests for each and every service, than we could be testing forever. People were always coming up with new services and asking how well LVS would do. The people who were asking had faster hardware than we did, and we had little idea what their hardware could do. It was quite reasonable for people, about to buy hardware and spend the time on an LVS install, to have some idea of the performance they'd get.
Here's the test setup (we used 2.0 and 2.2 kernels).
Figure 15. LVS Performance Test Setup
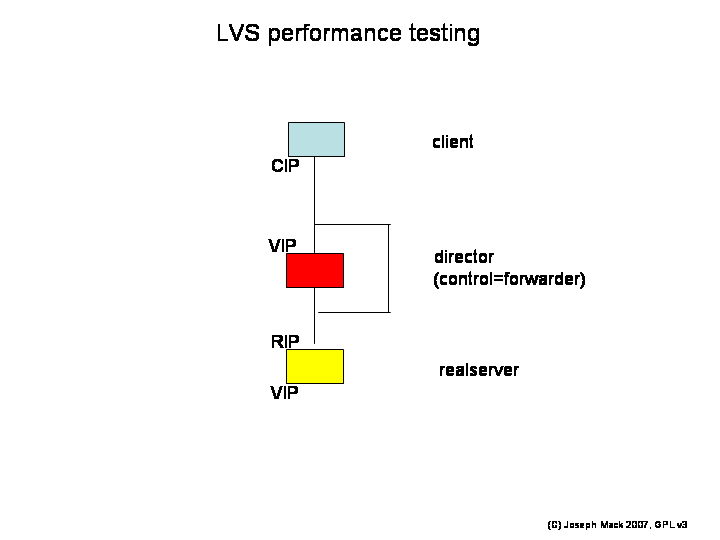 |
LVS Performance Test Setup
You're looking for the overhead from the LVS code, so the control box just forwards packets in both directions (no LVS loadbalancing).
With this setup, the only measurement you get is
- the round trip time for a packet (client-director-realserver-client).
The only possible performance parameters you can retrieve for a tcpip connection are
- the latency of transfer (time when the first bit arrived, mSec)
- the maximum throughput (rate of delivery of subsequent packets, Bps).
The only variable available (when the two end points have been decided), is
- the packet payload size.
The test then is to send different sized packets to the LVS, and time their return from the realserver. The software to do this is called netpipe. You first test each link separately to make sure they're working properly and then test the whole LVS. Here's some sample data, testing the client-director link.
Figure 16. Sample data, client-director (log-linear)
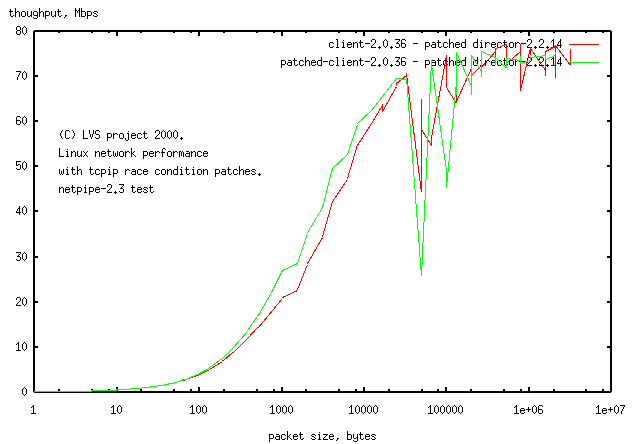 |
Sample Data, client-director.
You'll notice we weren't getting 100Mbps on 100Mbps ethernet. You need a 400MHz computer to do that. We had 75 and 133MHz computers back in those days. There's some wrinkles in the graph, that you don't see with modern hardware. The wrinkle at packet_size=32kB shows code/hardware with a 32kB buffer, that has problems with bigger packets. The graph tells you to be careful interpreting data from large packets.
This graph is log-linear and apart from showing wrinkles, doesn't tell you a whole lot. Here's a different run (with MTU size as the variable), with a slightly more useful log-log plot
Figure 17. Sample data, mtu as variable (log-log)
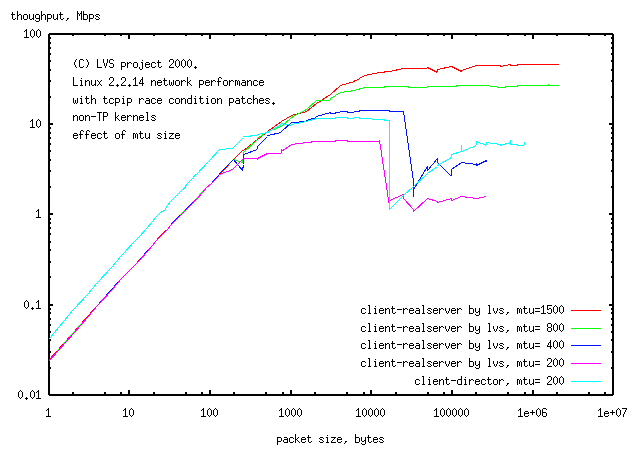 |
Sample Data, mtu as variable (log-log).
The log-log plot still shows the wrinkles, but now you can see the assymptotes of slope=0,1 expected for a process that has a latency and maximum throughput. This graph gives the maximum throughput, but doesn't give you the latency.
t=latency + packetsize/Vmax rearranging 1 packetsize/t (=vel) = Vmax(1-latency/t) ie y=(1-lat/x) #a hyperbola rearranging 2 packetsize/latency=Vmax(t/latency -1) The hyperbola will have a corner indicating the latency, which will be associated with a packetsize. For a straight tcpip connection, the latency is the time it takes to transfer an MTU sized packet. |
Instead of using the packet size as the independant variable, better is a parametric plot of the latency and throughput, each as a function of packet size. (the packet size increases from the bottom left to the top right.)
Figure 18. LVS test, parametric plot (log-log)
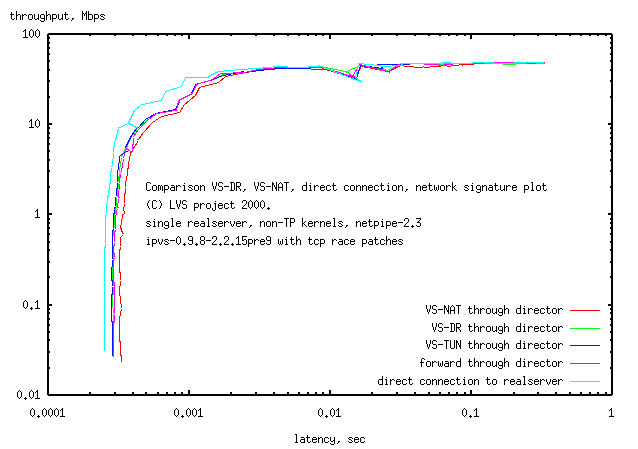 |
LVS test, parametric plot (log-log)
The data is for the 3 different forwarding methods of LVS and a comparison with a box just forwarding, and a comparison with a straight piece of wire. It turns out that the plots for LVS forwarding are little different from that of the box just forwarding. The plot for just the straight piece of ethernet cable has only slightly lower latency.
What we found
- the LVS code added at most 15% latency to small (0 byte) packets.
- there was no change in throughput:
-
the loadaverage on the director barely moved from zero, while the test client and realserver were operating
at high loadaverage
On some tests the loadaverage was over 5 (high for a 2.0 kernels) - on the client, the cursor would no longer respond to the mouse, while on the director, the cursor would respond normally.
The conclusion is that the tcpip stack, and not the LVS code, is the limiting factor in forwarding packets through the director. This shouldn't have been a surprise, considering the large number of copies done by the tcpip stack. So back to the original question of how many realservers an LVS director could support. It turns out, it was the wrong question. This was like asking how many servers a router could support. It's not the number of servers, it's the bandwidth the router/director could handle. When designing an LVS, you didn't need to ask anything about the performance of the LVS code. If you had 10 realservers each of which saturated their 100Mbps ethernet connection, then you had 1Gbps of traffic. You then picked hardware for the director that could saturate a 1Gbps ethernet link.
But how many people have a 1Gbps link to the internet? It turns out the plain ordinary commodity director hardware could saturate any link to the internet.
As for what you needed for each service (e.g. httpd, database), that was up to the realserver, not the director: can your webserver serve up 100Mbps of webpages?
Initially we saw the limitless scalability of LVS, without realising that it didn't take a whole lot of hardware to saturate your link to the internet. Functioning LVSs then have modest numbers of realservers (2-10) and 2 directors. It seems that the major functionality of LVS for many people is the ability to failout machines for maintenance (giving high availability).
Everyone needs security. Your machine is going to be sitting on the internet day-in and day-out. Potential intruders have lots of time to find your security weaknesses. Netbots aren't smart enough to know that your site has nothing interesting on it. Even if you don't care about security, others do and they won't be happy to find that your site was used to attack them. So yes Virginnia, you need security.
Here's how we apply standard security rules to an LVS.
A requirement of the LVS design is that the client sees only one machine - the client can't tell that multiple machines are involved (e.g. you don't want the client to be able to connect to the realservers directly).
The realservers are not exposed to clients
- RIPs are private addresses.
- There must be no routes to the realservers from outside: all packets to the realservers must go through the director.
- the only route from the realservers is VIP:80->0/0 (no other packets are allowed out of the LVS).
Connections from clients terminate at the realservers (i.e. the initial breach will occur on the realservers). An intruder on a realserver must not be able to hop outside the LVS. The way this is prevented is that an intruder on a realserver will be sending packets from the RIP and only having routes within the RIP network, can't send a packet outside of the LVS.
Because the realservers will be compromised first, all logins occur on the director, from a separate administrative network. You must not be able to login
- outside->director
- realserver->director
- realserver->realserver
Figure 19. LVS Security
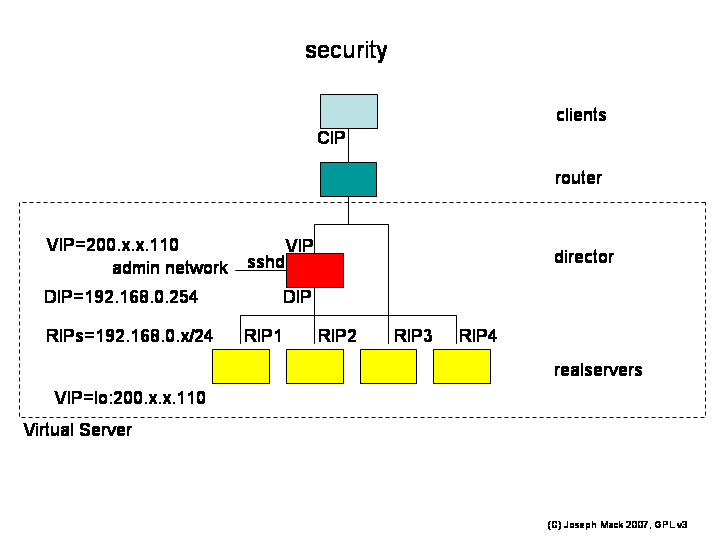 |
LVS Security
Standard security applies:
- DENY all, ACCEPT only expected packets:
- don't route all, only route expected packets (eschew default routes, which aren't needed)
Let's look at the packet route to see what restrictions we can place on the routing.
Packet path
- client->director
- director->realserver
- realserver->client
None of the hops have two way LVS traffic; each hop has only one-way traffic. This just fell out of the design and wasn't deliberate, but let's see how we can use this to make the LVS secure (assume your LVS is offering a virtual service at VIP:80.)
packets - director:VIP:80->0/0
What route should you have for packets from the director:VIP?
The director will never return a packet to the internet from VIP:80 as a result of a valid connection from a client - valid packets are forwarded to the realserver. icmp packets concerned with VIP:80 will originate at the realservers and be sent to the client through the router. You should only install a default route on the director, if you need one, but the LVS'ed service doesn't need to send packets from the VIP->0/0. The only function then of a default route on the director would be to allow an intruder, who has gained access to the director, to send packets to the internet. On the director, you shouldn't have any routes from the VIP, default or otherwise.
Quiz: what should you do with a SYN packet for VIP:81 (or VIP:22)? (assume no service listening on the director:VIP:81, VIP:22).
(This isn't the only answer.) The IETF says to return a "connection refused" icmp packet, which courteously lets the client know as soon as possible, that there is no service listening on that port (otherwise the client's connection will hang till it times out). To send this icmp packet, you need a default route for icmp packets from the VIP, which we've just decided is a really bad idea, so we didn't install a default route. To stop the director generating "connection refused" icmp packets, which don't have a route, you should drop all incoming packets to !(VIP:80). Ports scanners then will hang till they timeout.
The standard LVS director then has no routes from VIP and has a firewall blocking !(VIP:80). As a consequence you can't ping the VIP (unless you add a default route for ping packets from the VIP).
Packets on the RIP network
- non-LVS packets: realserver-realserver (private src,dest addresses)
- LVS packets 0/0->VIP:80
no default routes here, only accept packets from the internet for VIP:80 and allow expected packets between the realservers.
packets from the realserver to the client: VIP:80->0/0
The only route needed is VIP:80->0/0. No packets from VIP:!80 can get out and with no route from the router to the realserver, no packets of any sort can get from the internet to the realserver. An intruder on one of the realservers has a limited number of places to send packets.
It's hard to tell how many people are using LVS. People who come up on the mailing list don't tell us what they're using it for, and we don't ask - it seems a bit instrusive to do so on a public mailing list. We just answer their questions. We get the occasional comment from people surveying load balancers, trying to figure out what they should use, that there's a whole series of commercial load balancers using LVS underneath.
Being part of an internet project:
- I've learned a lot.
- It's nice to have all help gratefully accepted.
-
I've met face to face with some smart and nice people, that I first knew through the mailing list.
I've had them stay at my home. I'll hit them up for a free vacation myself sometime.
- Maybe made a little difference to the world
We've had offers of modest amounts of money in thanks, but since there's no LVS Foundation to accept such funds, and no way to equitably split money or to account for what happened to it (apart from posting our IRS returns on the LVS webpage), we've declined the money. I guess we'll just keep coding till we go broke.
Joining an internet project
- find a project that you think is really neat and you could spend some time on (>year?)
-
check that the mailing list treats people courteously, even those who ask stupid questions.
you could be working with these people for a while. Make sure they're rational and good communicators.
- start doing something you like or you think is useful (remember you're doing it for fun and because you want to)
- don't do something just because someone else suggested it (you should expect $ for that).